入門 機械学習による異常検知 ~正規分布に従うデータからの異常検知(1)~
この記事は『入門 機械学習による異常検知』(井出 剛 著)で学んだことを自分なりに解釈し、例として記載されているRコードをベースに異常検知手順をまとめた記事になります。本記事独自のRコードが多く含まれ、純粋な書籍記載のコードではないのでご注意下さい。
1変数正規分布に基づく異常検知
1変数が正規分布に従うと仮定できる場合の異常検知手法になります。サンプルデータはRのcarパッケージに含まれるDavisデータです。
データの確認
さっそくDavisデータの中身を見てみましょう。carパッケージを読み込み、Davisデータを少しだけ見てみます。
# Carパッケージをインストール(インストール済みの場合は実行不要) install.packages("car") # Carパッケージを読み込み library("car") # Davisデータの読み込みと確認 data(Davis) # 組み込みデータセットのDavisを読み込み、データフレーム化 head(Davis) # Davisを先頭から6行だけ表示
sex weight height repwt repht 1 M 77 182 77 180 2 F 58 161 51 159 3 F 53 161 54 158 4 M 68 177 70 175 5 F 59 157 59 155 6 M 76 170 76 165
Davisデータの中身はこのようになります。左から性別、体重、身長、体重(自己申告)、身長(自己申告)です。データ数は200データあります。今回は1変数ですので、体重を使用します。
分布モデルの作成
まずはヒストグラムで体重の分布を確認します
# ヒストグラムの表示 # 階級の分割数(breaks):10 # 縦軸の種類(freq):F(密度) weight <- Davis$weight hist(weight, breaks=10, freq=F)
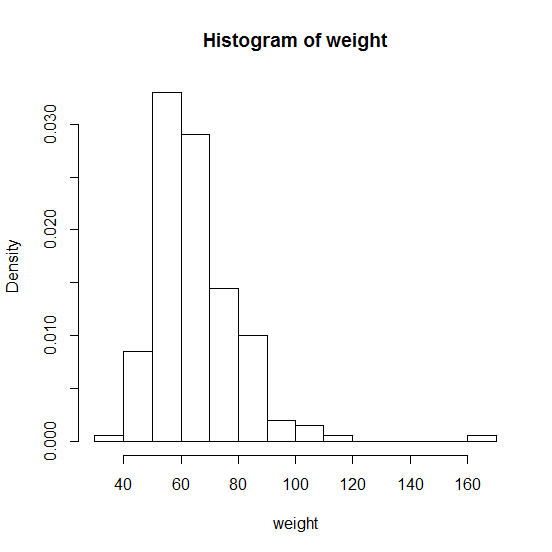
出力結果はこのようになります。外れ値はありますが、今回はデータクレンジングは実施せずにそのまま使用します。(私が実際に分析するのであれば、外れ値が発生した原因を調べ、例えば入力ミス等の理由であれば除去します。)
体重のヒストグラムを確認したところ、概ね正規分布に従っていると言えそうなため、正規分布でモデルを作成します。それでは、正規分布で必要なパラメータである平均と分散を求めましょう。
# 標本平均と標本分散を算出 mu <- mean(Davis$weight) sd2 <- mean((Davis$weight - mu)^2) mu sd2
> mu [1] 65.8 > sd2 [1] 226.72
標本の平均は65.8、分散は226.72でした。これらのパラメータを持つ正規分布をモデルとして使用していきます。
念のため、体重のヒストグラムと平均65.8、分散226.72の正規分布の当てはまりを見てみましょう。
# 正規分布をヒストグラムに重ねて表示 sd <- sqrt(sd2) # ヒストグラム作成用の変数(標本の標準偏差) weight <- sort(weight) # weightを昇順にソート(グラフ描画のための処理) lines(weight, dnorm(weight, mu, sd))
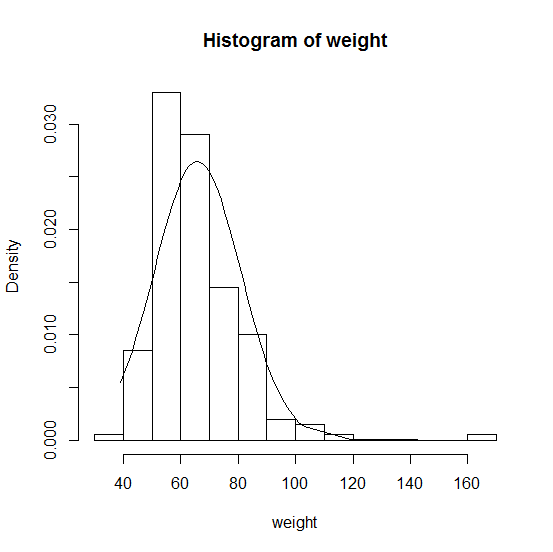 グラフを見てみると、概ね合っていそうなのが分かります。
グラフを見てみると、概ね合っていそうなのが分かります。
分布モデルから異常度を算出
異常度は分布モデルの負の対数尤度として求めることができます。 正規分布の計算式は以下の通りです。
上記の式の負の対数を計算すると次のようになります。
ここで、第1項はxに依存しないため無視し、式の形を綺麗にするために2を掛けて、異常度を算出する式を定義します。
式を見ると分かる通り、異常度を計算する観測値xの平均値からの距離を標準偏差で割ることで正規化しています。それでは、異常度を計算してみましょう。
# 異常度の計算 a <- ((Davis$weight-mu)/sd)^2 head(Davis$weight) # 体重を先頭から6行だけ表示 head(a) # 異常度を先頭から6行だけ表示
> head(Davis$weight) # 体重を先頭から6行だけ表示 [1] 77 58 53 68 59 76 > head(a) # 異常度を先頭から6行だけ表示 [1] 0.55328158 0.26834862 0.72265349 0.02134792 0.20395201 0.45889203
平均は65.8kgですので、この中で平均に最も近い68kgの異常度が0.02134792と一番小さくなっています。逆に平均から最も離れた53kgの異常度が0.72265349と一番大きくなっています。このようにして、今回作成した分布モデルに対するすべての体重データの異常度を求めることができました。
異常度から異常検知のための閾値を算出
今回はDavisデータの体重は正規分布に従うとして異常度を算出しました。今後測定する体重に関してもDavisデータの体重と同じ正規分布に独立に従い、かつデータ数Nが1よりも十分大きい場合、異常度は自由度1、スケール因子1のカイ二乗分布に従うそうです。この理論は「ホテリング理論」と呼ばれるものです。ホテリング理論に従い、カイ二乗分布を使用して閾値を設定しましょう。今回は0.5%とします。
# 閾値の計算 th <- qchisq(0.995, 1) # 自由度1のカイ二乗分布で確率0.995となる値 th
> th [1] 7.879439
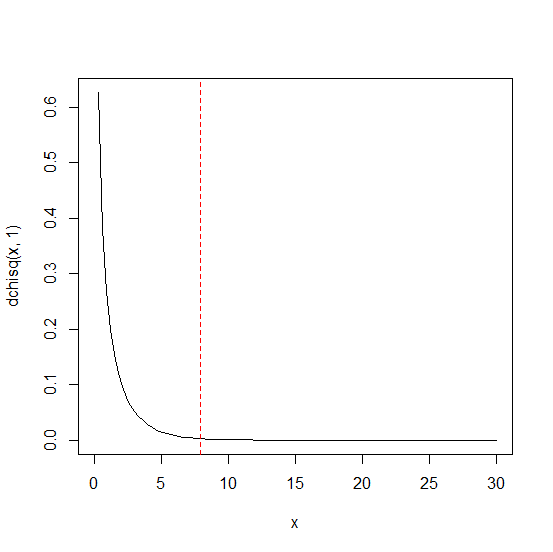
閾値は7.879439と求められました。ちなみに自由度1のカイ二乗分布(黒色実線)と閾値(赤色点線)をグラフにすると以下のようになります。
# 自由度1のカイ二乗分布のグラフ(0<x<30) curve(dchisq(x,1), from=0, to=30) abline(v=th, lty=2, col="red") # 値がthの垂線を引く(点線、赤色)
それでは、すべての異常度を散布図でプロットし、閾値も表示してみましょう。
# 異常度と閾値をプロット plot(a, xlab="標本番号", ylab="異常度") abline(h=th, col="red", lty=2) # 値がthの水平線を引く(赤色、点線)
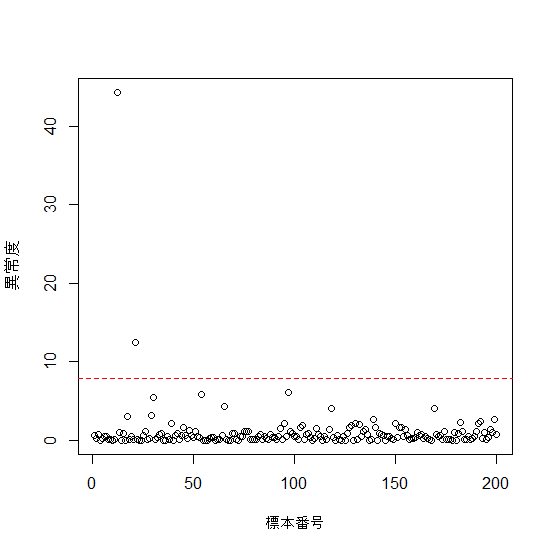
一つだけ異常度が突出して高いデータがあることが分かります。これは最初のヒストグラムからも明らかだった異常なデータです。これを見ると「これを取り除いて再度やり直した方が良いのではないか。」という疑問が出てくると思いますが、その考えは間違っていないようです。本の中で、それは合理的な手法だと言ってくれています。
このようにして求めた閾値を利用して、測定値が異常かどうかを判定することで、例えば体重の入力ミスを検知したり、過度の肥満の人を見つけたりすることができるようになります。