宿泊旅行統計調査データを縦持ちデータに加工する
前回の訪日外客数データに続き、インバウンド関連のオープンデータ加工シリーズの第二弾として、観光庁の宿泊旅行統計調査データの加工について掲載します。訪日外客数データは、どんな国や地域から日本を訪れた人がどの位いるのかを調べることができました。今回の宿泊旅行統計調査データは、どんな国や地域から日本を訪れた人がどの県にどれだけ宿泊したのかを調べることができます。インバウンドで大切な消費額の観点から自分たちの県に関する分析をしてみるのはいかがでしょうか。
宿泊旅行統計調査データ
観光庁が公開している統計情報の一つに宿泊旅行統計調査データがあります。全国の宿泊情報について実際に調査した結果を統計情報として掲載しているものです。データの前提となる情報については観光庁のウェブサイトからご確認下さい。
今回はこの中にある調査結果のうち、第2次速報にある「集計結果(推移表)」のExcelデータを取り扱います。
このExcelは非常に難解な内容になっており、1シート目は目次です。良く見て行くと段々と慣れてくるのですが、最初は面食らうと思います。今回は都道府県別に訪日外国人がどの位宿泊したのかが分かる「都道府県別 外国人延べ宿泊者数 推移表 (月別)」のシートを対象にします。例によって、データ分析には使いにくいExcelで作り込まれた形になっていますので、使いやすい形に加工するコードを公開します。コードはPythonで記載します。
宿泊旅行統計調査データのデータ加工コード
訪日外客数データを縦持ちデータに加工するコードは以下になります。
# Pandasのインポート
import pandas as pd
# ファイルのURLを指定(集計結果(推移表)データ及びデータのあるディレクトリを指定して下さい)
fileURL = "集計結果(推移表).xlsx"
# Excelファイルを読み込み(ブックとして読み込み)
book_ef = pd.ExcelFile(fileURL)
# 読み込んだExcelファイル(ブック)からシートを取り出す
# 2行目までスキップ
# 読み込んだ1行目をヘッダーとして読み込まない(3-2:6)
sheet_df = book_ef.parse(sheet_name=6, skiprows=2, header=None)
# 和暦の欠損値を穴埋め
sheet_df.iloc[0] = sheet_df.iloc[0].fillna(method='ffill')
# 和暦と月を結合し、列カラムとして読み込み
sheet_df.columns = sheet_df.iloc[0] + sheet_df.iloc[1]
# 不要な行を削除(和暦:0、月:1、全国:2)
sheet_df = sheet_df.drop(sheet_df.index[[0, 1, 2]])
# 和暦と月をすべてアンピボット
sheet_df = pd.melt(sheet_df, id_vars=sheet_df.columns.values[:1], var_name='(和暦)', value_name='外国人延べ宿泊者数')
# 列名をリストで変更
sheet_df.columns = ['都道府県', '年月(和暦)', '外国人延べ宿泊者数']
# 都道府県番号の列を追加
sheet_df.insert(0, '都道府県番号', '')
# 都道府県番号列に都道府県番号を代入
sheet_df['都道府県番号'] = sheet_df['都道府県'].str[0:2]
# 都道府県列に都道府県を代入
sheet_df['都道府県'] = sheet_df['都道府県'].str[2:6]
# CSV形式で出力
sheet_df.to_csv('tourism_stay_statistics.csv', index=False, encoding='shift_jis')
データ加工のポイント
対象となるシートは1枚なのでシートの扱いは簡単なのですが、年が和暦で記載されていることや結合セルを月のセルの上に被せる形で見せていることが最大のネックです。和暦のデータを月ごとに繰り返し、年と月を結合した上でアンピボットしています。もし和暦を西暦に変換したい場合は、別途和暦と西暦の変換マスタを用意すれば簡単に変換できます。
まとめ
インバウンド関連のオープンデータとして観光庁が公開している宿泊旅行統計調査データをデータ分析に使いやすい形に加工するコードを紹介しました。自分たちの県に宿泊している訪日外国人はどの位いるのか、近隣の県はどうなのか、月ごとにシーズナリティはあるのかを分析することができますので、是非ご活用頂けますと幸いです。
訪日外客数データを縦持ちデータに加工する
2020年現在、新型コロナウィルスの影響で観光業界は出口の見えない状況になってしまっています。特にインバウンドは以前の面影なく、観光で日本を訪れる外国人はゼロになってしまっています。
そんな中でもこの先訪れる観光の再開に向けて、インバウンドに関わる人たちは準備を進めていかなければなりません。今この時に基本に立ち返り、インバウンドのターゲット国に関する分析をしてみるのはいかがでしょうか。
訪日外客数データ
日本政府観光局(JNTO)は、日本を訪れた外国人の数を公表しています。ただ残念なことに、多くの行政のオープンデータの例に漏れず、データ分析には使いにくいExcelで作り込まれた形での公開となっており、データ活用の幅を狭めてしまっています。そこで今回はこの訪日外国人数の統計データをデータ分析に使いやすい形に加工するコードを公開します。コードはPythonで記載します。
訪日外客数データは日本政府観光局(JNTO)のウェブサイト上で公開されています。
今回はこの中にある訪日外客数(年表)のうち、「国籍/月別 訪日外客数」のExcelデータを取り扱います。
訪日外客数データのデータ加工コード
訪日外客数データを縦持ちデータに加工するコードは以下になります。
# Pandasのインポート
import pandas as pd
# Excelファイルの読み込み
book_ef = pd.ExcelFile('/since2003_visitor_arrivals.xlsx')
# Excelファイルのシート名を取得
sheet_names = book_ef.sheet_names
# 変換した訪日外客数データを格納するデータフレームの定義
visitor_arrivals_df = pd.DataFrame(columns=['市場', '年', '月', '訪日外客数'])
# 1つずつシートを取り出して、変換処理を実行
for name in sheet_names:
# 2020の場合
if name == '2020':
# ヘッダー3行を飛ばしてシートをデータフレームとして読み込み
sheet_df = book_ef.parse(name, skiprows=3)
# 列名を変更
sheet_df = sheet_df.rename(columns={'Unnamed: 0':'市場', '1月':'1', '2月':'2', '3月':'3', '4月':'4', '5月':'5', '6月':'6', '7月':'7', '8月':'8', '9月':'9', '10月':'10', '11月':'11', '12月':'12'})
# 中東地域の処理として、市場(小項目)を市場列にコピー
sheet_df.iloc[14, 0] = sheet_df.iat[14, 1]
sheet_df.iloc[15, 0] = sheet_df.iat[15, 1]
sheet_df.iloc[16, 0] = sheet_df.iat[16, 1]
# 中東地域の市場名にある先頭の全角空白を削除
sheet_df.iloc[14, 0] = sheet_df.iloc[14, 0].replace(' ', '')
sheet_df.iloc[15, 0] = sheet_df.iloc[15, 0].replace(' ', '')
sheet_df.iloc[16, 0] = sheet_df.iloc[16, 0].replace(' ', '')
# 不要な列を削除(市場(小項目):1、伸び率:3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25、累計と伸び率:26-27)
sheet_df = sheet_df.drop(sheet_df.columns[[1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 26, 27]], axis=1)
# 不要な行を削除(総数:0、アジア計:1、中東地域:13、ヨーロッパ計:20、北アメリカ計:40、南アメリカ計:45、オセアニア計48、フッター:53-54)
sheet_df = sheet_df.drop(sheet_df.index[[0, 1, 13, 20, 40, 45, 48, 53, 54]])
# 月をアンピボット
sheet_df = pd.melt(sheet_df, id_vars=sheet_df.columns.values[:1], var_name='月', value_name='訪日外客数')
# 年の列を追加
sheet_df.insert(1, '年', name)
# 訪日外客数のデータフレーム追加
visitor_arrivals_df = pd.concat([visitor_arrivals_df, sheet_df])
# 2016-2019の場合
elif name=='2019' or name=='2018' or name=='2017' or name=='2016':
# ヘッダー3行を飛ばしてシートをデータフレームとして読み込み
sheet_df = book_ef.parse(name, skiprows=3)
# 列名を変更
sheet_df = sheet_df.rename(columns={'Unnamed: 0':'市場', '1月':'1', '2月':'2', '3月':'3', '4月':'4', '5月':'5', '6月':'6', '7月':'7', '8月':'8', '9月':'9', '10月':'10', '11月':'11', '12月':'12'})
# 不要な列を削除(伸び率:2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24、累計と伸び率:25-26)
sheet_df = sheet_df.drop(sheet_df.columns[[2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 25, 26]], axis=1)
# 不要な行を削除(総数:0、アジア計:1、ヨーロッパ計:18、北アメリカ計:38、南アメリカ計:43、オセアニア計:46、フッター:51-52)
sheet_df = sheet_df.drop(sheet_df.index[[0, 1, 18, 20, 38, 43, 46, 51, 52]])
# 月をアンピボット
sheet_df = pd.melt(sheet_df, id_vars=sheet_df.columns.values[:1], var_name='月', value_name='訪日外客数')
# 年の列を追加
sheet_df.insert(1, '年', name)
# 訪日外客数のデータフレーム追加
visitor_arrivals_df = pd.concat([visitor_arrivals_df, sheet_df])
# 2015以前の場合
else:
# ヘッダー3行を飛ばしてシートをデータフレームとして読み込み
sheet_df = book_ef.parse(name, skiprows=3)
# 列名を変更
sheet_df = sheet_df.rename(columns={'Unnamed: 0':'市場', '1月':'1', '2月':'2', '3月':'3', '4月':'4', '5月':'5', '6月':'6', '7月':'7', '8月':'8', '9月':'9', '10月':'10', '11月':'11', '12月':'12'})
# 不要な列を削除(伸び率:2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24、累計と伸び率:25-26)
sheet_df = sheet_df.drop(sheet_df.columns[[2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 25, 26]], axis=1)
# 不要な行を削除(総数:0、アジア計:1、ヨーロッパ計:15、北アメリカ計:34、南アメリカ計:38、オセアニア計:40、フッター:44-45)
sheet_df = sheet_df.drop(sheet_df.index[[0, 1, 15, 34, 38, 38, 40, 44, 45]])
# 月をアンピボット
sheet_df = pd.melt(sheet_df, id_vars=sheet_df.columns.values[:1], var_name='月', value_name='訪日外客数')
# 年の列を追加
sheet_df.insert(1, '年', name)
# 訪日外客数のデータフレーム追加
visitor_arrivals_df = pd.concat([visitor_arrivals_df, sheet_df])
# CSV形式で出力
visitor_arrivals_df.to_csv('visitor_arrivals_processed.csv', index=False, encoding='shift_jis')
データ加工のポイント
Excelデータを加工する上でのポイントとして一番のネックになるのは、ある年を境に国や地域が追加されている点です。2020年から中東地域が追加されており、2020年のシートのデータ加工コードとそれ以前のシートのデータ加工コードは異なります。また、中東地域は大項目と小項目に分かれており、ここも心が折れるポイントの一つです。2016年にも国や地域の変更があったようで、2015年以前のコードはまた変える必要があります。
また、Excelでは良くやる方法ですが、年ごとにシートが分かれているのもデータ加工がしにくいポイントの一つです。一つずつシートを処理しながらシート名から年の情報を取り出し、データに追加していかなければなりません。
今回のようにExcel形式で公開されてるデータは、多くの場合Excelを使う人のために作られています。今回も、アジアやヨーロッパのような単位での合計や全体の総計が記載されているのですが、データ分析をしたい人にとっては余計なデータです。同様に前年同月と比べた伸び率も記載されているのですが、こちらも余計なデータになります。それぞれ行ごと、列ごと削除する必要があります。 (一般に、データ分析ではデータを加工する前の純粋な値のみをデータとして残しておき、合計や総計、前年同月比等はデータ加工途中で計算したり、BIツール上で表現する際に改めて計算したりします。)
まとめ
今回は観光業界のオープンデータの一つとして、日本政府観光局(JNTO)が公表している訪日外客数データをデータ分析に使いやすい形に加工するコードを紹介しました。日本に人が多く訪れている国や地域はどこなのか、どこの国や地域の訪日数が伸びているのかを分析することができますので、是非ご活用頂けますと幸いです。
(2020.12.31追記)
中東地域の市場(小項目)の値の先頭に全角空白が残ってしまっていたため、全角空白を削除する処理を追加しました。
Rの組み込みデータセット 一覧
Rには標準でインストールされている組み込みデータセットがあります。統計学の歴史を感じるような古いデータも多いですが、有名なirisのように勉強会等でサンプルとして使うことができる便利なデータもあります。どのようなデータセットがあるのかを見てみましょう。
組み込みデータセットの一覧
組み込みデータセットの一覧を表示します。
# 組み込みデータセットの一覧を表示 data()
別のウィンドウに組み込みデータセットの一覧が表示されます。実行すると組み込みのデータセットはdatasetsパッケージに含まれていることが分かります。datasetsパッケージはRに標準で組み込まれているパッケージの一つです。 (実行日は2017年10月22日です。)
Data sets in package ‘datasets’:
AirPassengers Monthly Airline Passenger Numbers 1949-1960
BJsales Sales Data with Leading Indicator
BJsales.lead (BJsales)
Sales Data with Leading Indicator
BOD Biochemical Oxygen Demand
CO2 Carbon Dioxide Uptake in Grass Plants
ChickWeight Weight versus age of chicks on different
diets
DNase Elisa assay of DNase
EuStockMarkets Daily Closing Prices of Major European Stock
Indices, 1991-1998
Formaldehyde Determination of Formaldehyde
HairEyeColor Hair and Eye Color of Statistics Students
Harman23.cor Harman Example 2.3
Harman74.cor Harman Example 7.4
Indometh Pharmacokinetics of Indomethacin
InsectSprays Effectiveness of Insect Sprays
JohnsonJohnson Quarterly Earnings per Johnson & Johnson
Share
LakeHuron Level of Lake Huron 1875-1972
LifeCycleSavings Intercountry Life-Cycle Savings Data
Loblolly Growth of Loblolly pine trees
Nile Flow of the River Nile
Orange Growth of Orange Trees
OrchardSprays Potency of Orchard Sprays
PlantGrowth Results from an Experiment on Plant Growth
Puromycin Reaction Velocity of an Enzymatic Reaction
Seatbelts Road Casualties in Great Britain 1969-84
Theoph Pharmacokinetics of Theophylline
Titanic Survival of passengers on the Titanic
ToothGrowth The Effect of Vitamin C on Tooth Growth in
Guinea Pigs
UCBAdmissions Student Admissions at UC Berkeley
UKDriverDeaths Road Casualties in Great Britain 1969-84
UKgas UK Quarterly Gas Consumption
USAccDeaths Accidental Deaths in the US 1973-1978
USArrests Violent Crime Rates by US State
USJudgeRatings Lawyers' Ratings of State Judges in the US
Superior Court
USPersonalExpenditure
Personal Expenditure Data
UScitiesD Distances Between European Cities and Between
US Cities
VADeaths Death Rates in Virginia (1940)
WWWusage Internet Usage per Minute
WorldPhones The World's Telephones
ability.cov Ability and Intelligence Tests
airmiles Passenger Miles on Commercial US Airlines,
1937-1960
airquality New York Air Quality Measurements
anscombe Anscombe's Quartet of 'Identical' Simple
Linear Regressions
attenu The Joyner-Boore Attenuation Data
attitude The Chatterjee-Price Attitude Data
austres Quarterly Time Series of the Number of
Australian Residents
beaver1 (beavers) Body Temperature Series of Two Beavers
beaver2 (beavers) Body Temperature Series of Two Beavers
cars Speed and Stopping Distances of Cars
chickwts Chicken Weights by Feed Type
co2 Mauna Loa Atmospheric CO2 Concentration
crimtab Student's 3000 Criminals Data
discoveries Yearly Numbers of Important Discoveries
esoph Smoking, Alcohol and (O)esophageal Cancer
euro Conversion Rates of Euro Currencies
euro.cross (euro) Conversion Rates of Euro Currencies
eurodist Distances Between European Cities and Between
US Cities
faithful Old Faithful Geyser Data
fdeaths (UKLungDeaths)
Monthly Deaths from Lung Diseases in the UK
freeny Freeny's Revenue Data
freeny.x (freeny) Freeny's Revenue Data
freeny.y (freeny) Freeny's Revenue Data
infert Infertility after Spontaneous and Induced
Abortion
iris Edgar Anderson's Iris Data
iris3 Edgar Anderson's Iris Data
islands Areas of the World's Major Landmasses
ldeaths (UKLungDeaths)
Monthly Deaths from Lung Diseases in the UK
lh Luteinizing Hormone in Blood Samples
longley Longley's Economic Regression Data
lynx Annual Canadian Lynx trappings 1821-1934
mdeaths (UKLungDeaths)
Monthly Deaths from Lung Diseases in the UK
morley Michelson Speed of Light Data
mtcars Motor Trend Car Road Tests
nhtemp Average Yearly Temperatures in New Haven
nottem Average Monthly Temperatures at Nottingham,
1920-1939
npk Classical N, P, K Factorial Experiment
occupationalStatus Occupational Status of Fathers and their Sons
precip Annual Precipitation in US Cities
presidents Quarterly Approval Ratings of US Presidents
pressure Vapor Pressure of Mercury as a Function of
Temperature
quakes Locations of Earthquakes off Fiji
randu Random Numbers from Congruential Generator
RANDU
rivers Lengths of Major North American Rivers
rock Measurements on Petroleum Rock Samples
sleep Student's Sleep Data
stack.loss (stackloss)
Brownlee's Stack Loss Plant Data
stack.x (stackloss) Brownlee's Stack Loss Plant Data
stackloss Brownlee's Stack Loss Plant Data
state.abb (state) US State Facts and Figures
state.area (state) US State Facts and Figures
state.center (state) US State Facts and Figures
state.division (state)
US State Facts and Figures
state.name (state) US State Facts and Figures
state.region (state) US State Facts and Figures
state.x77 (state) US State Facts and Figures
sunspot.month Monthly Sunspot Data, from 1749 to "Present"
sunspot.year Yearly Sunspot Data, 1700-1988
sunspots Monthly Sunspot Numbers, 1749-1983
swiss Swiss Fertility and Socioeconomic Indicators
(1888) Data
treering Yearly Treering Data, -6000-1979
trees Girth, Height and Volume for Black Cherry
Trees
uspop Populations Recorded by the US Census
volcano Topographic Information on Auckland's Maunga
Whau Volcano
warpbreaks The Number of Breaks in Yarn during Weaving
women Average Heights and Weights for American
Women
Use ‘data(package = .packages(all.available = TRUE))’
to list the data sets in all *available* packages.
最後に表示されているのは、利用可能なパッケージのデータセットを表示させる方法になります。色んなパッケージをインストールしている場合はかなりの数のデータセットが表示されます。
# 利用可能なパッケージのデータセットの一覧を表示 data(package = .packages(all.available = TRUE))
分析手法を試してみるにしてもまずデータがないと始まりません。組み込みのデータセットや各パッケージに含まれているデータセットを活用していきましょう。
入門 機械学習による異常検知 ~正規分布に従うデータからの異常検知(1)~
この記事は『入門 機械学習による異常検知』(井出 剛 著)で学んだことを自分なりに解釈し、例として記載されているRコードをベースに異常検知手順をまとめた記事になります。本記事独自のRコードが多く含まれ、純粋な書籍記載のコードではないのでご注意下さい。
1変数正規分布に基づく異常検知
1変数が正規分布に従うと仮定できる場合の異常検知手法になります。サンプルデータはRのcarパッケージに含まれるDavisデータです。
データの確認
さっそくDavisデータの中身を見てみましょう。carパッケージを読み込み、Davisデータを少しだけ見てみます。
# Carパッケージをインストール(インストール済みの場合は実行不要) install.packages("car") # Carパッケージを読み込み library("car") # Davisデータの読み込みと確認 data(Davis) # 組み込みデータセットのDavisを読み込み、データフレーム化 head(Davis) # Davisを先頭から6行だけ表示
sex weight height repwt repht 1 M 77 182 77 180 2 F 58 161 51 159 3 F 53 161 54 158 4 M 68 177 70 175 5 F 59 157 59 155 6 M 76 170 76 165
Davisデータの中身はこのようになります。左から性別、体重、身長、体重(自己申告)、身長(自己申告)です。データ数は200データあります。今回は1変数ですので、体重を使用します。
分布モデルの作成
まずはヒストグラムで体重の分布を確認します
# ヒストグラムの表示 # 階級の分割数(breaks):10 # 縦軸の種類(freq):F(密度) weight <- Davis$weight hist(weight, breaks=10, freq=F)
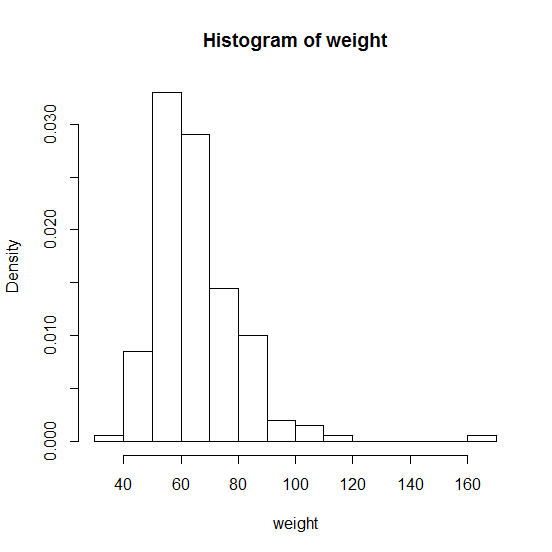
出力結果はこのようになります。外れ値はありますが、今回はデータクレンジングは実施せずにそのまま使用します。(私が実際に分析するのであれば、外れ値が発生した原因を調べ、例えば入力ミス等の理由であれば除去します。)
体重のヒストグラムを確認したところ、概ね正規分布に従っていると言えそうなため、正規分布でモデルを作成します。それでは、正規分布で必要なパラメータである平均と分散を求めましょう。
# 標本平均と標本分散を算出 mu <- mean(Davis$weight) sd2 <- mean((Davis$weight - mu)^2) mu sd2
> mu [1] 65.8 > sd2 [1] 226.72
標本の平均は65.8、分散は226.72でした。これらのパラメータを持つ正規分布をモデルとして使用していきます。
念のため、体重のヒストグラムと平均65.8、分散226.72の正規分布の当てはまりを見てみましょう。
# 正規分布をヒストグラムに重ねて表示 sd <- sqrt(sd2) # ヒストグラム作成用の変数(標本の標準偏差) weight <- sort(weight) # weightを昇順にソート(グラフ描画のための処理) lines(weight, dnorm(weight, mu, sd))
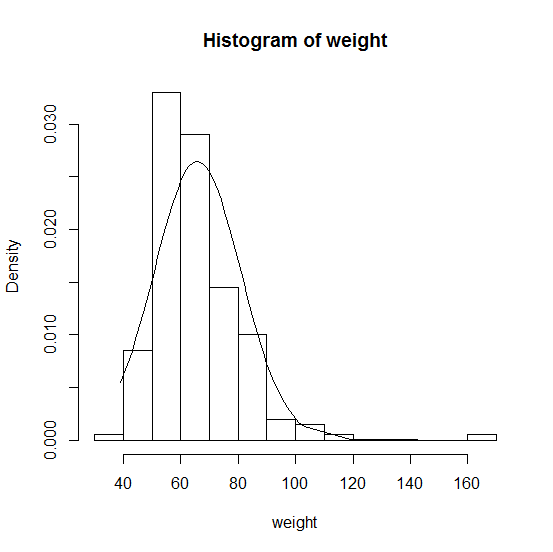 グラフを見てみると、概ね合っていそうなのが分かります。
グラフを見てみると、概ね合っていそうなのが分かります。
分布モデルから異常度を算出
異常度は分布モデルの負の対数尤度として求めることができます。 正規分布の計算式は以下の通りです。
上記の式の負の対数を計算すると次のようになります。
ここで、第1項はxに依存しないため無視し、式の形を綺麗にするために2を掛けて、異常度を算出する式を定義します。
式を見ると分かる通り、異常度を計算する観測値xの平均値からの距離を標準偏差で割ることで正規化しています。それでは、異常度を計算してみましょう。
# 異常度の計算 a <- ((Davis$weight-mu)/sd)^2 head(Davis$weight) # 体重を先頭から6行だけ表示 head(a) # 異常度を先頭から6行だけ表示
> head(Davis$weight) # 体重を先頭から6行だけ表示 [1] 77 58 53 68 59 76 > head(a) # 異常度を先頭から6行だけ表示 [1] 0.55328158 0.26834862 0.72265349 0.02134792 0.20395201 0.45889203
平均は65.8kgですので、この中で平均に最も近い68kgの異常度が0.02134792と一番小さくなっています。逆に平均から最も離れた53kgの異常度が0.72265349と一番大きくなっています。このようにして、今回作成した分布モデルに対するすべての体重データの異常度を求めることができました。
異常度から異常検知のための閾値を算出
今回はDavisデータの体重は正規分布に従うとして異常度を算出しました。今後測定する体重に関してもDavisデータの体重と同じ正規分布に独立に従い、かつデータ数Nが1よりも十分大きい場合、異常度は自由度1、スケール因子1のカイ二乗分布に従うそうです。この理論は「ホテリング理論」と呼ばれるものです。ホテリング理論に従い、カイ二乗分布を使用して閾値を設定しましょう。今回は0.5%とします。
# 閾値の計算 th <- qchisq(0.995, 1) # 自由度1のカイ二乗分布で確率0.995となる値 th
> th [1] 7.879439
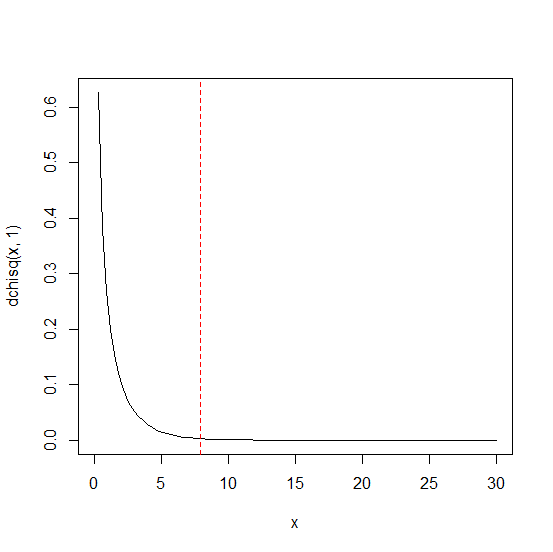
閾値は7.879439と求められました。ちなみに自由度1のカイ二乗分布(黒色実線)と閾値(赤色点線)をグラフにすると以下のようになります。
# 自由度1のカイ二乗分布のグラフ(0<x<30) curve(dchisq(x,1), from=0, to=30) abline(v=th, lty=2, col="red") # 値がthの垂線を引く(点線、赤色)
それでは、すべての異常度を散布図でプロットし、閾値も表示してみましょう。
# 異常度と閾値をプロット plot(a, xlab="標本番号", ylab="異常度") abline(h=th, col="red", lty=2) # 値がthの水平線を引く(赤色、点線)
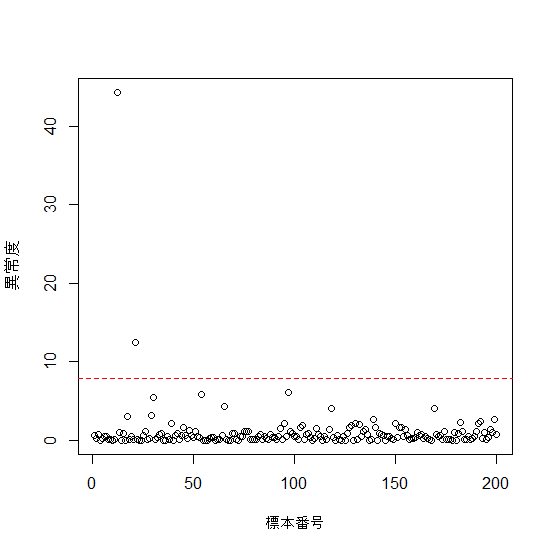
一つだけ異常度が突出して高いデータがあることが分かります。これは最初のヒストグラムからも明らかだった異常なデータです。これを見ると「これを取り除いて再度やり直した方が良いのではないか。」という疑問が出てくると思いますが、その考えは間違っていないようです。本の中で、それは合理的な手法だと言ってくれています。
このようにして求めた閾値を利用して、測定値が異常かどうかを判定することで、例えば体重の入力ミスを検知したり、過度の肥満の人を見つけたりすることができるようになります。
はてなブログの編集「見たまま」で改行の行間を少なくする方法
はてなブログを始めて、最初の記事を書くなりいきなり壁に当たりました。改行をした時に自分が思っているよりも行間が空いてしまうのです。その解決方法はHTMLを知っていれば分かるのかも知れませんが、すぐに気が付くのが難しいと思ったので記事にしてみました。
改行の行間を少なくする方法
方法は単純です。普段「Enter」で改行するところを、「Shift + Enter」で改行をしてあげるだけです。実際に見比べてみましょう。
「Enter」で改行をした場合は↓のようになります。
「Enter」改行の1行目
「Enter」改行の2行目
「Enter」改行の4行目(3行目は空行)
「Shift + Enter」で改行をした場合は↓のようになります。
「Shift + Enter」改行の1行目
「Shift + Enter」改行の2行目
「Shift + Enter」改行の4行目(3行目は空行)
かなり違うのが分かりますね。
改行の行間が異なる理由
改行の行間が2種類ある理由は、OfficeのWordと同じだと考えると分かりやすいと思います。Wordで「Enter」を押すと『段落』が変わり、「Shift + Enter」を押すと『行』が変わります。
これと同じで、はてなブログでも「Enter」を押すと『段落』を記述する<p>タグ(Paragraph = 段落)、「Shift + Enter」を押すと『改行』を記述する<br>タグ(Break = 改行)が記述されます。編集「見たまま」タブの隣の「HTML編集」タブで見てみると良く分かります。
「Enter」で改行をした場合のHTML
<p>「Enter」改行の1行目</p>
<p>「Enter」改行の2行目</p>
<p> </p>
<p>「Enter」改行の4行目(3行目は空行)</p>
「Shift + Enter」で改行をした場合のHTML
<p>
「Shift + Enter」改行の1行目<br />
「Shift + Enter」改行の2行目<br />
<br />
「Shift + Enter」改行の4行目(3行目は空行)<br />
</p>
単純にブログを書きたいだけなのですが、そこはWebの世界。プログラムフリーの世界はなかなか遠いですね。